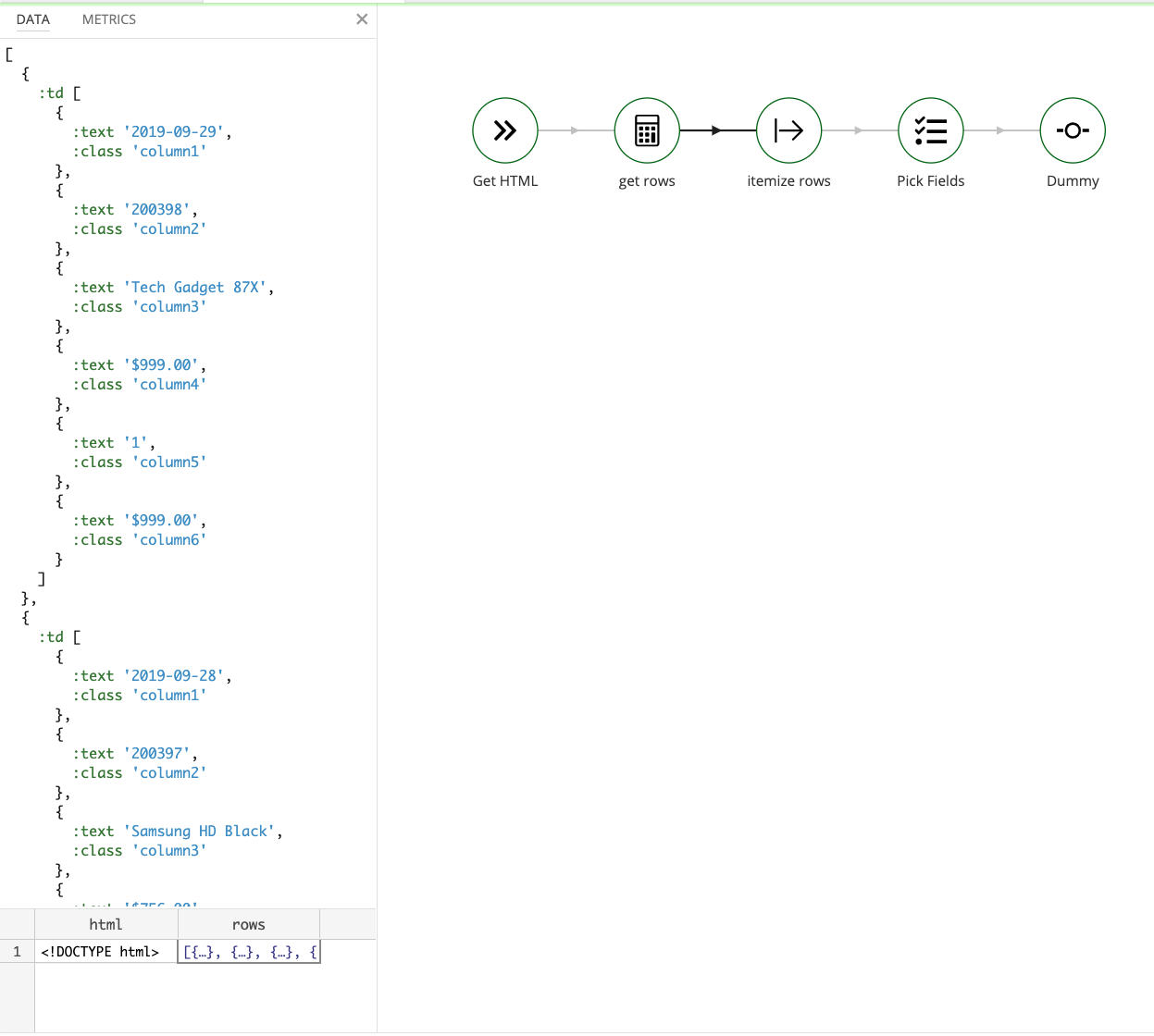
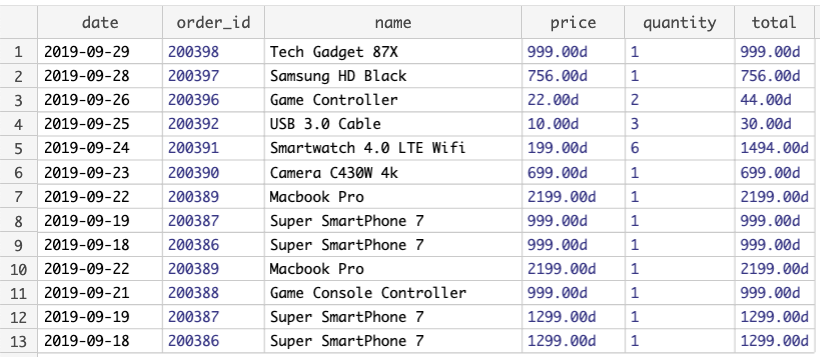
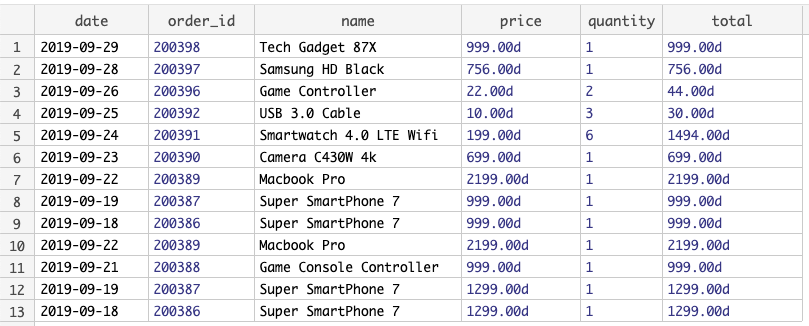
For this challenge, we work with a legacy system that we can only access by reading a HTML page from it. The HTML contains a table that looks like this:
| Date | Order ID | Name | Price | Quantity | Total |
|---|---|---|---|---|---|
| 2019-09-29 | 200398 | Tech Gadget 87X | $999.00 | 1 | $999.00 |
| 2019-09-28 | 200397 | Samsung HD Black | $756.00 | 1 | $756.00 |
| 2019-09-26 | 200396 | Game Controller | $22.00 | 2 | $44.00 |
| 2019-09-25 | 200392 | USB 3.0 Cable | $10.00 | 3 | $30.00 |
| 2019-09-24 | 200391 | Smartwatch 4.0 LTE Wifi | $199.00 | 6 | $1494.00 |
| 2019-09-23 | 200390 | Camera C430W 4k | $699.00 | 1 | $699.00 |
| 2019-09-22 | 200389 | Macbook Pro | $2199.00 | 1 | $2199.00 |
| 2019-09-19 | 200387 | Super SmartPhone 7 | $999.00 | 1 | $999.00 |
| 2019-09-18 | 200386 | Super SmartPhone 7 | $999.00 | 1 | $999.00 |
| 2019-09-22 | 200389 | Macbook Pro | $2199.00 | 1 | $2199.00 |
| 2019-09-21 | 200388 | Game Console Controller | $999.00 | 1 | $999.00 |
| 2019-09-19 | 200387 | Super SmartPhone 7 | $1299.00 | 1 | $1299.00 |
| 2019-09-18 | 200386 | Super SmartPhone 7 | $1299.00 | 1 | $1299.00 |
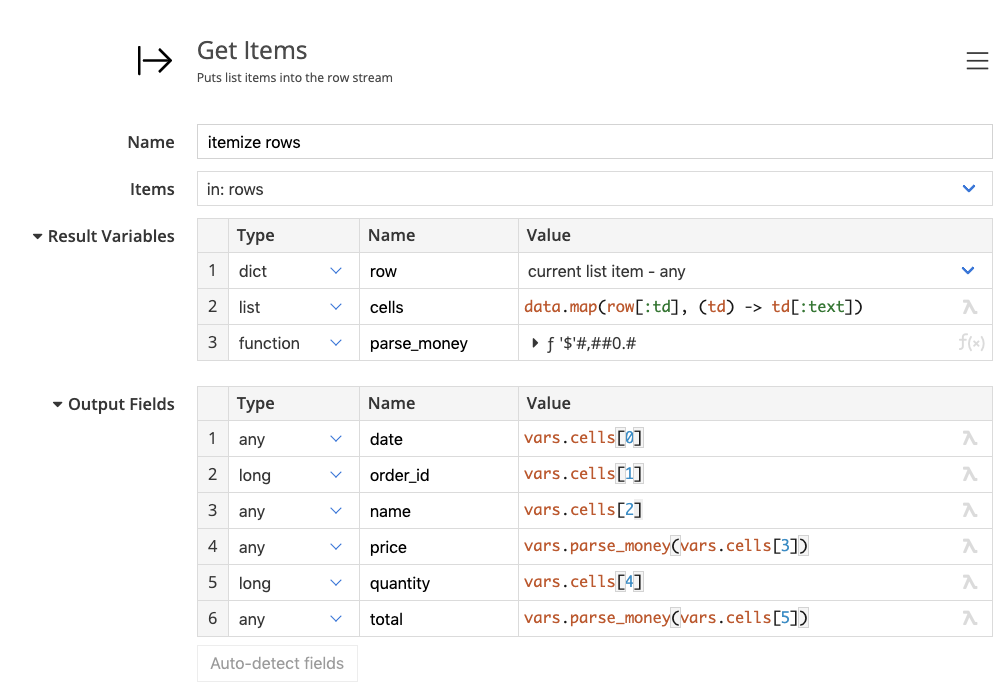
Our task is to extract the information from the table, so we can put it into a database. We should be able to extract information into fields like this:
Begin with start.dfl (13.1 KB) . It includes the HTML table.
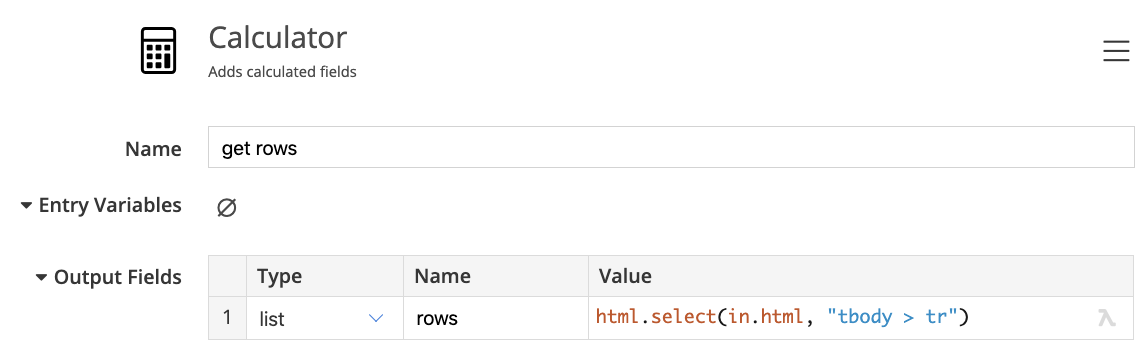
Hint: use the html.select function to select all rows, and extract the text from child cells.