For this challenge, we’re looking at a book catalog given to us in the form of books.xml (23.3 KB) .
Data Source
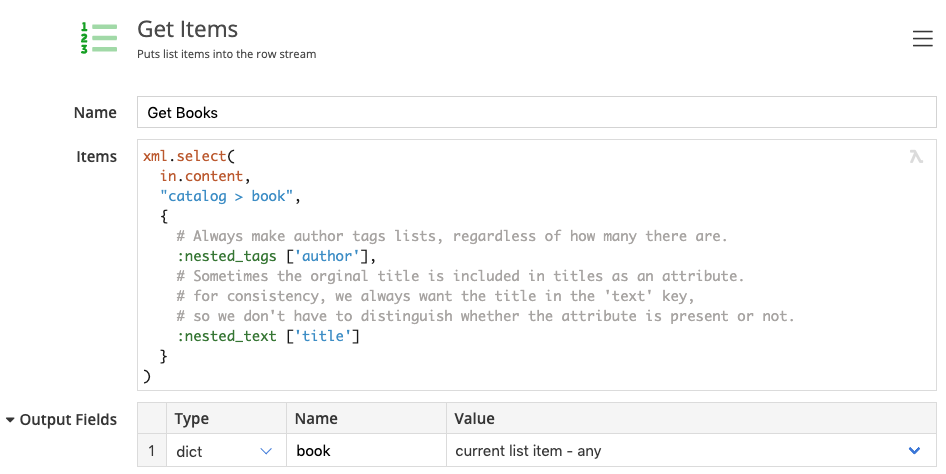
It’s an XML file containing entries that look like this:
<book isbn="439554934" original_pub_year="1997">
<series entry="1">Harry Potter</series>
<title original="Harry Potter and the Philosopher's Stone">Harry Potter and the Sorcerer's Stone</title>
<authors>
<author>J.K. Rowling</author>
<author>Mary GrandPré</author>
</authors>
</book>
The format is as follows:
- We get the isbn and original year of publication as attributes on the
booktag - If the book is part of a series we get its name in the
seriestag. It has anentryattribute telling us where the book belongs in the series. - The title of the book is given in the
titletag. There is an optional attribute that holds the original title, in case the book appears as a translation or the title was edited for our edition. - The authors of the book come as a list of entries in the
authorstag.
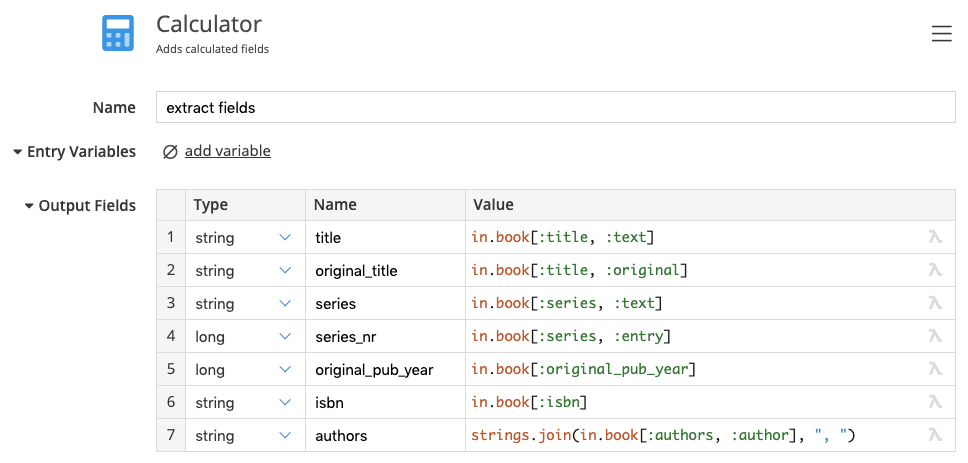
Transformation Target
We need to convert this file into an Excel sheet preserving all information. If there are multiple authors, we put them into a single field, and separate them by a comma.
The output file should have the following structure:
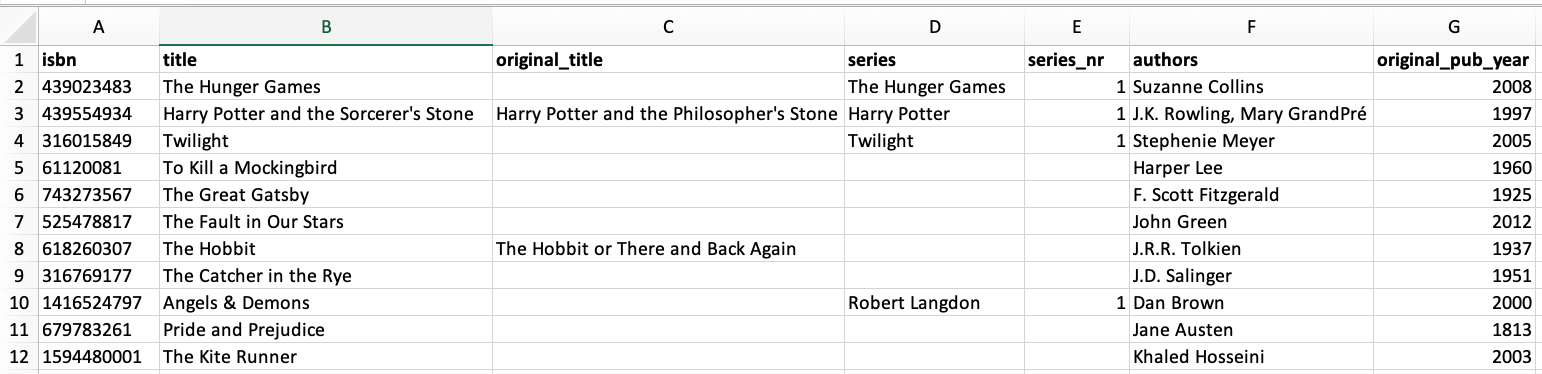
Grab the books.xml (23.3 KB) source file and create a data flow that produces the required file.
Hint: use the xml.select function to convert the xml to structured data. Note that the
:nested_tagsand:nested_textoptions can make it easier to consistently handle author tag multiplicity and optional attributes respectively.