There are many ways to transform the data. The solution I am presenting groups the incoming rows by id, forming a dict of the key-value pairs in the process.
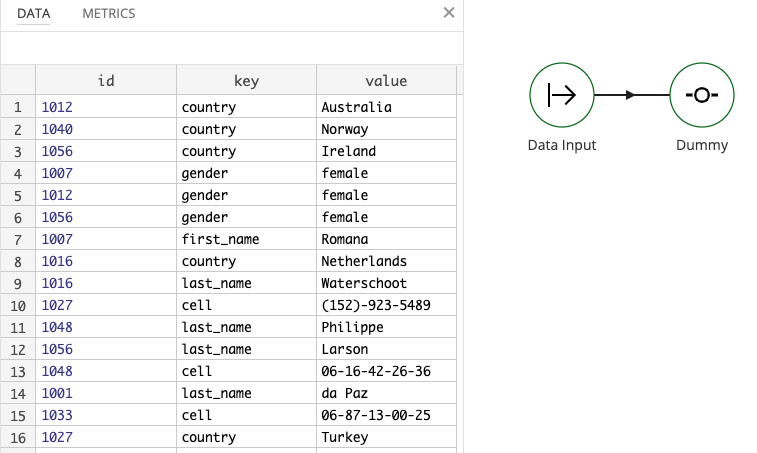
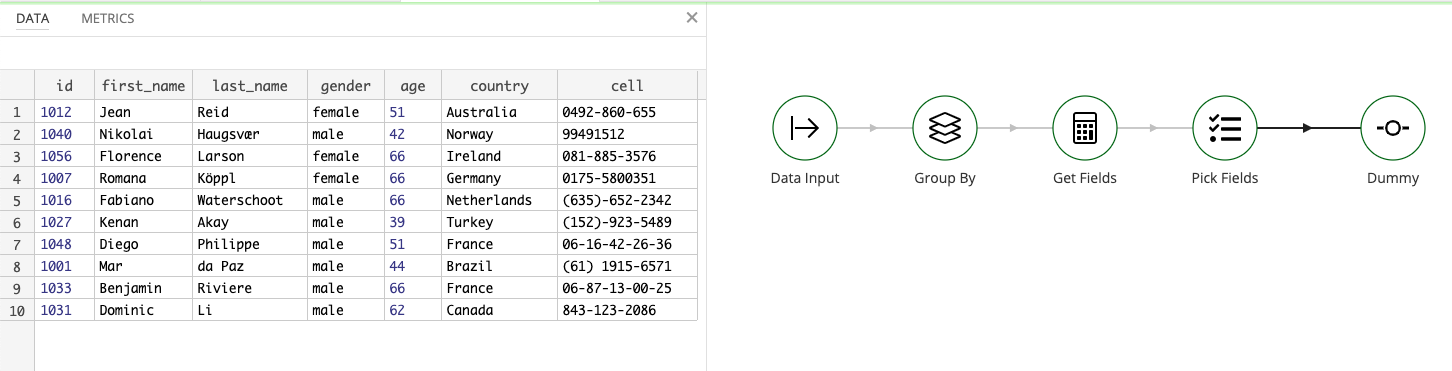
We are starting out with data shaped like this:
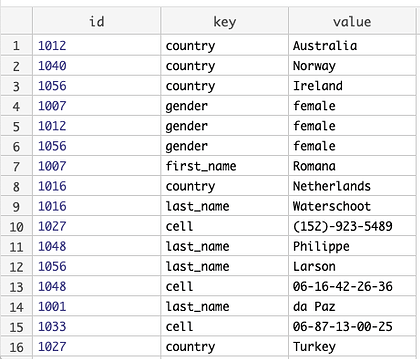
If we use the group by step to group by id, we can easily collect all rows that belong to a record. But since the Group By step supports custom aggregators, we can use one to construct the record, while we’re collecting the rows that go into it.
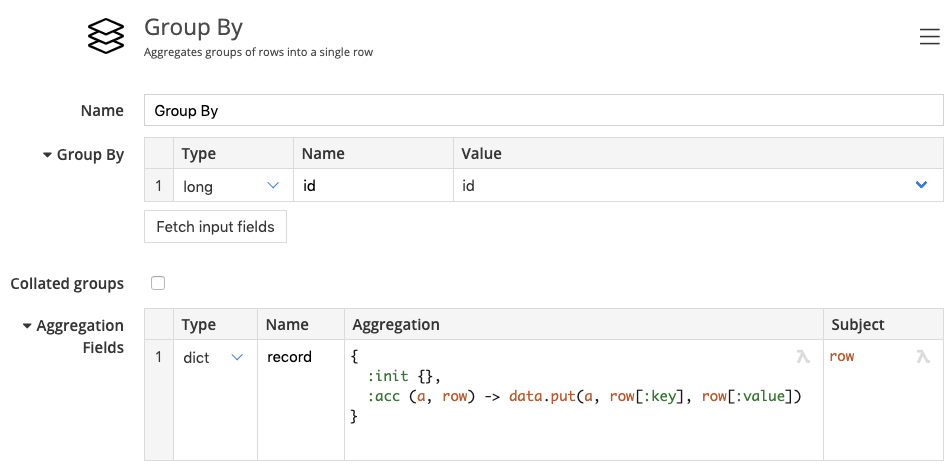
Here’s the configuration of the aggregator step:
We’re using a custom aggregator where we start with {} and keep adding entries from collected rows using data.put.
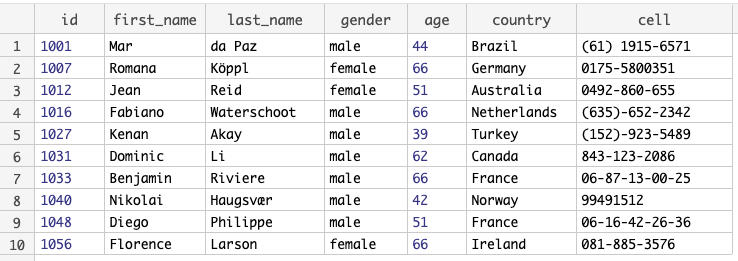
As a result we get a record with all fields per id.
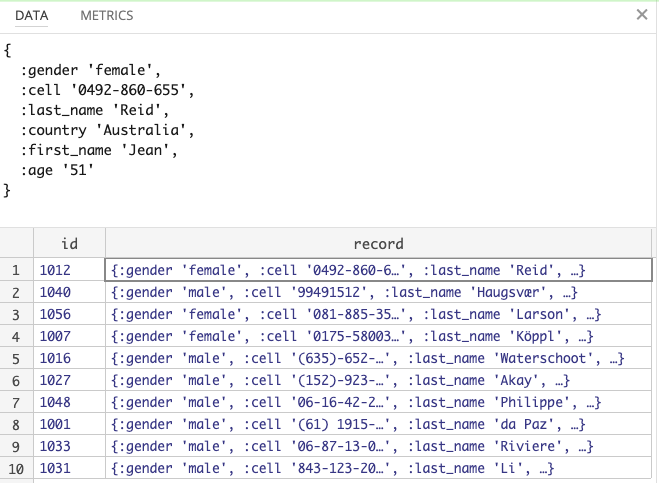
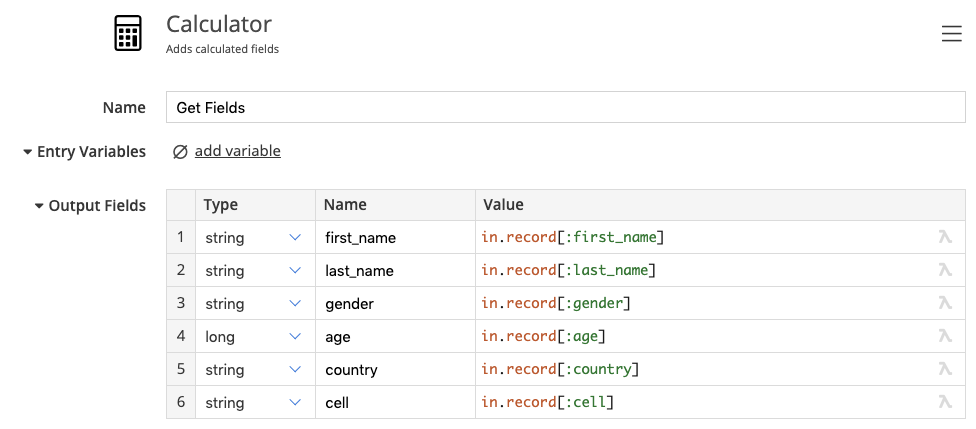
To arrive at the final structure we just extract the fields into the top level using a calculator:
We can drop our temporary record field and arrive at the target structure:
Here’s the solution.dfl (80.6 KB) file.