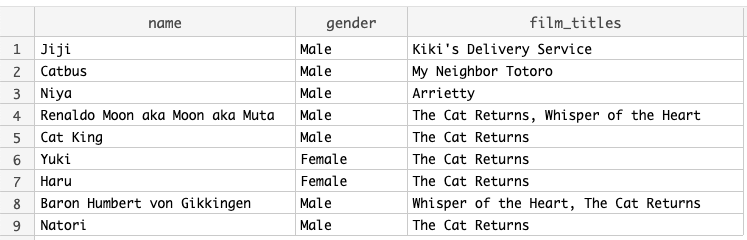
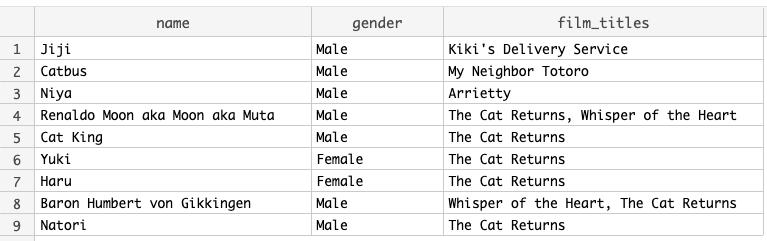
Finding all cat characters and their films
The basic idea of the solution.dfl (40.0 KB) is to
- fetch all films and index their titles by url for a quick lookup later
- fetch all species, and find the cat species url
- fetch the cat species url to retrieve all people belonging to the cat species
- look up all found people via their own url, and extract their name gender, and films they appear in
- look up the film titles in the film index
Fetching all films
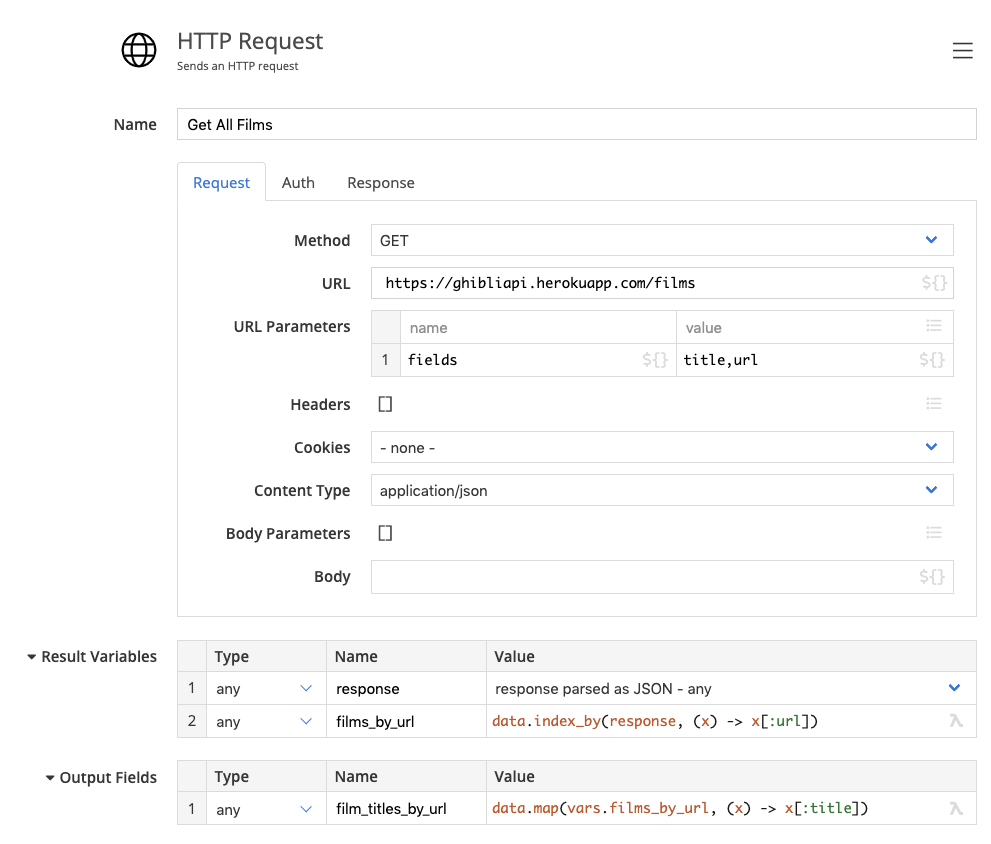
We starts by getting all films from the API, and indexing them by their url for easy lookup later.
The HTTP step is configured as follows:
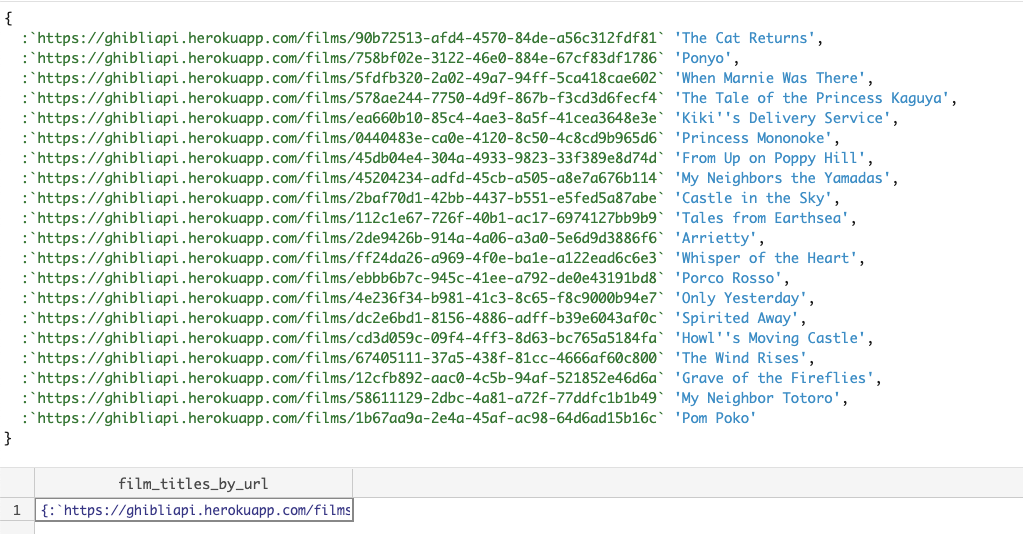
Our output field looks like this:
We’re going to keep that data around and use it as a lookup table later.
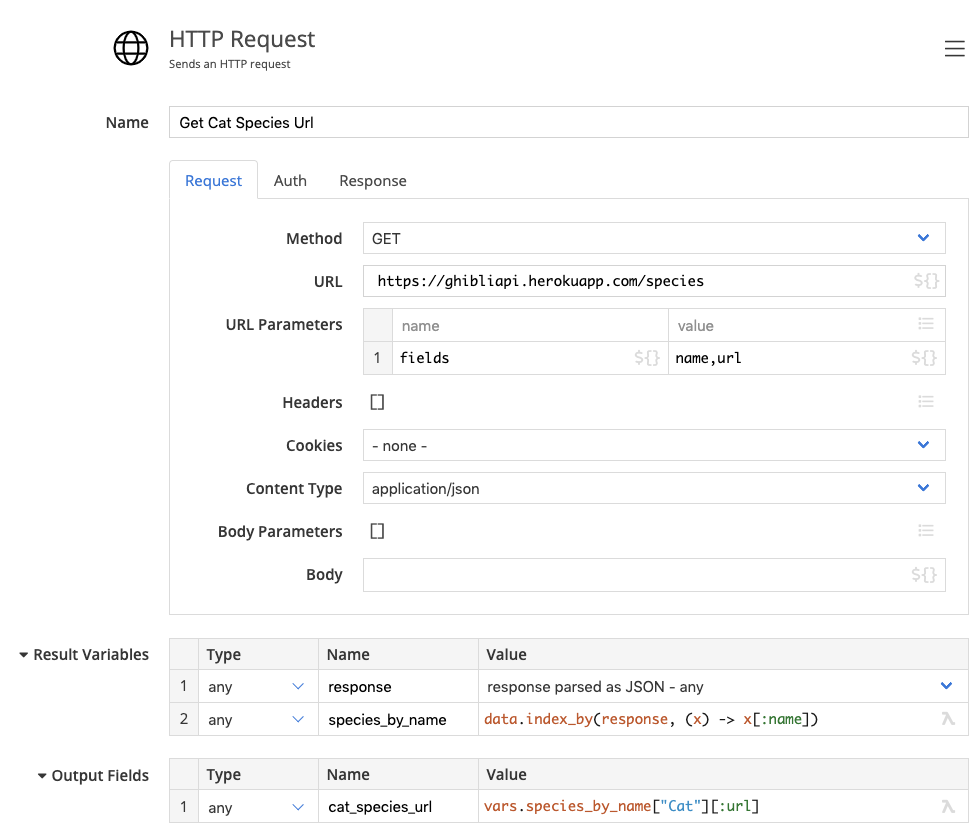
Finding the cat species url
Our web API does not allow us to fetch a species by name, and while fetching all species with all references is possible, we can also first find the cat species url, and then do a targeted call.
The Get Cat Species Url step asks for all species, but limits the fields to name and url, then finds the url for the species named “Cat”.
Our output field gets the value
https://ghibliapi.herokuapp.com/species/603428ba-8a86-4b0b-a9f1-65df6abef3d3
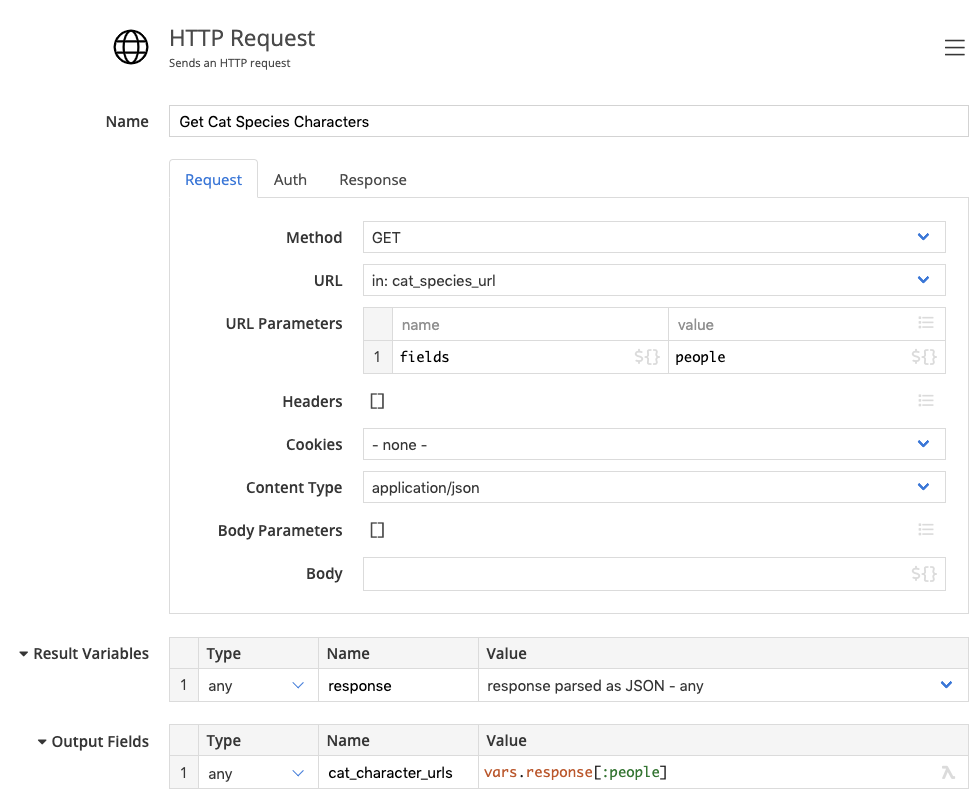
Finding all cats
We can call that url, and ask the API to respond with all people belonging to the species:
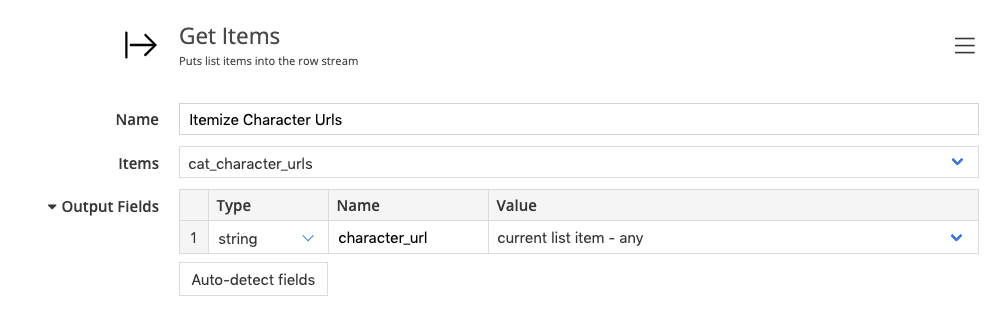
We’re getting a list back and can itemize the elements into the row stream.
Fetching individual cat details
We can now call each of the cat’s people url, to find their properties, including their name, gender, and list of films they appear in.
Our new output fields look like this:
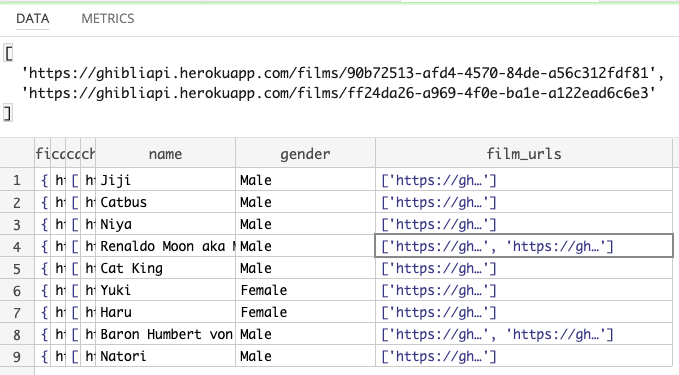
We get a list of film urls for each character.
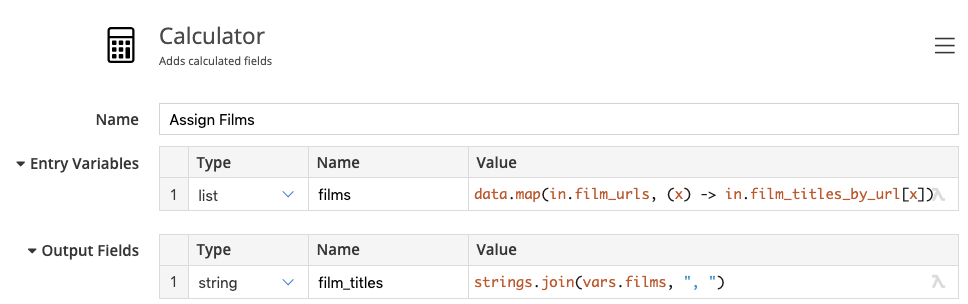
Looking up film titles
Recall that we’ve prepared an index of all films in the beginning of the flow. We can now use that table to look up the film titles, by using the character’s film_urls as indexes into our film_titles_by_url field.
As a final touch, we convert the the list of titles to a comma separated list, so it becomes a string.
Cleaning up
We can use the pick fields step to get rid of fields we don’t need any more, and we’re left with the desired result.