
We have several data suppliers reporting monthly sales numbers in CSV files.
Details of file formats differ across suppliers. File encoding, headers, separators, order and names of columns, date and number formats - they are all different.
Every file contains at least the following fields: date, sku, quantity, and price.
Our task is to consolidate all files and create one CSV file that contains all that data in a single format.
In this tutorial, we’ll accomplish that with a single data flow.
Pick up the data_driven_input_example.zip (424.7 KB) files to follow along. The archive contains all input files, the metadata file, and the solution flow.
The files
input
├── bishop_unlimited
│ ├── 2019-01.csv
│ ├── 2019-02.csv
| | ...
│ └── 2019-12.csv
├── chan_and_co
│ ├── 2019-01.csv
│ ├── 2019-02.csv
| | ...
│ └── 2019-12.csv
├── parkes_industries
│ ├── 2019-01.csv
│ ├── 2019-02.csv
| | ...
│ └── 2019-12.csv
└── raymond_corp
├── 2019-01.csv
├── 2019-02.csv
| ...
└── 2019-12.csv
4 directories, 48 files
We have four different suppliers, each with their own file format. Let’s take a look at them:
Raymond Corp
Their files look like this:
date;sku;quantity;price
2019-01-01;tty/m/or;62;$724.84
2019-01-01;nil/s/gr;55;$794.28
...
- there is a header line
-
;is the separator -
uuuu-MM-ddis the date format - price is prepended with a dollar sign
- files are in UTF-8 encoding
Bishop Unlimited
Their files look like this:
"n","p","sku","d"
"98","832.02","she/m/yl","01/21/2019"
"18","233.82","cor/m/or","01/21/2019"
...
- there is a header line with abbreviated field names
- fields are in order
quantity, price, sku, date -
"is used to enclose fields -
,is the separator -
MM/dd/uuuuis the date format - files are in UTF-8 encoding
Parkes Industries
Their files look like this:
20002080|USD 615.23|dev/s/bk|20190120|77
20002307|USD 295.63|dev/s/bk|20190120|37
...
- there is no header line
- fields are in order
serial, price, sku, date, quantity - there is an extra column containing a serial number that is of no interest to us
-
|is the separator - price is prepended by
USD - date format is
uuuuMMdd - files are in UTF-16 little endian encoding
Chan and Co
Their files look like this:
---
--- Data Export for 01/2019
---
lix/s/bl 425.27 43 2019-01-19
dev/s/bk 441.45 65 2019-01-19
...
- there are extra three lines of prologue
- there is no header line
- fields are in order
sku, price, quantity, date - the tab character
\tis the separator -
uuuu-MM-ddis the date format - files are in UTF-8 encoding
The Target Format
We need to consolidate all files into a single output file of the following format:
source;date;sku;quantity;price
raymond_corp;2019-01-01;tty/m/or;62;724.84
bishop_unlimited;2019-01-19;dev/s/bk;65;441.45
...
The Solution
We’ll keep track of the metadata about our file formats and use it to dynamically determine how to process a file at runtime.
Our metadata boils down to the following information:
| source | charset | skip_lines | named_columns | separator | enclosure | date_col | date_format | sku_col | quantity_col | price_col | price_format |
|---|---|---|---|---|---|---|---|---|---|---|---|
| raymond_corp | UTF-8 | 0 | true | ; | date | uuuu-MM-dd | sku | quantity | price | $0.00 | |
| bishop_unlimited | UTF-8 | 0 | true | , | " | d | MM/dd/uuuu | sku | n | p | 0.00 |
| parkes_industries | UTF-16LE | 0 | false | | | 3 | uuuuMMdd | 2 | 4 | 1 | USD 0.00 | |
| chan_and_co | UTF-8 | 3 | false | TAB | 3 | uuuu-MM-dd | 0 | 2 | 1 | 0.## |
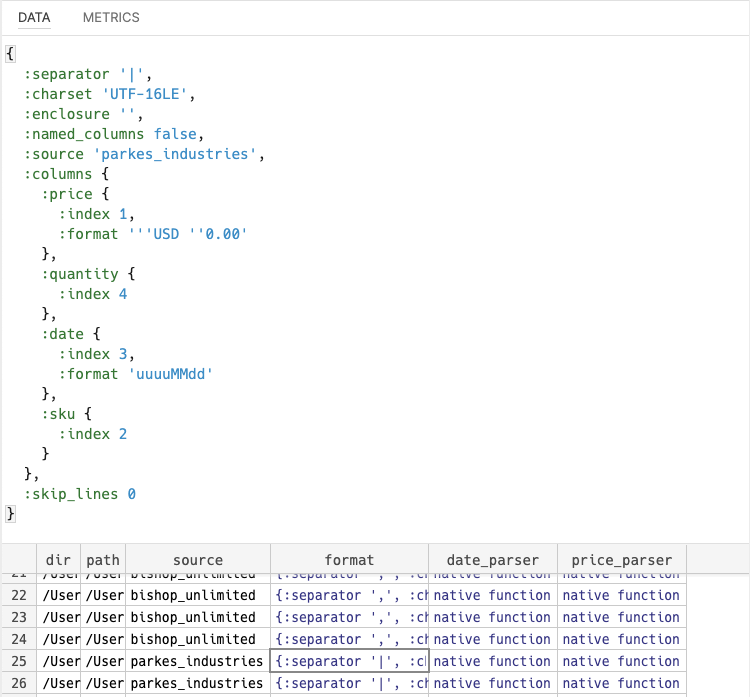
We’ll keep that information in a JSON file structured like so:
[
{
"source": "raymond_corp",
"charset": "UTF-8",
"skip_lines": 0,
"separator": ";",
"named_columns": true,
"enclosure": "",
"columns": {
"date": {
"index": "date",
"format": "uuuu-MM-dd"
},
"sku": {
"index": "sku"
},
"quantity": {
"index": "quantity"
},
"price": {
"index": "price",
"format": "'$'0.00"
}
}
},
... additional supplier formats ...
]
With that information to hand, we can apply the necessary configuration dynamically for each processed file.
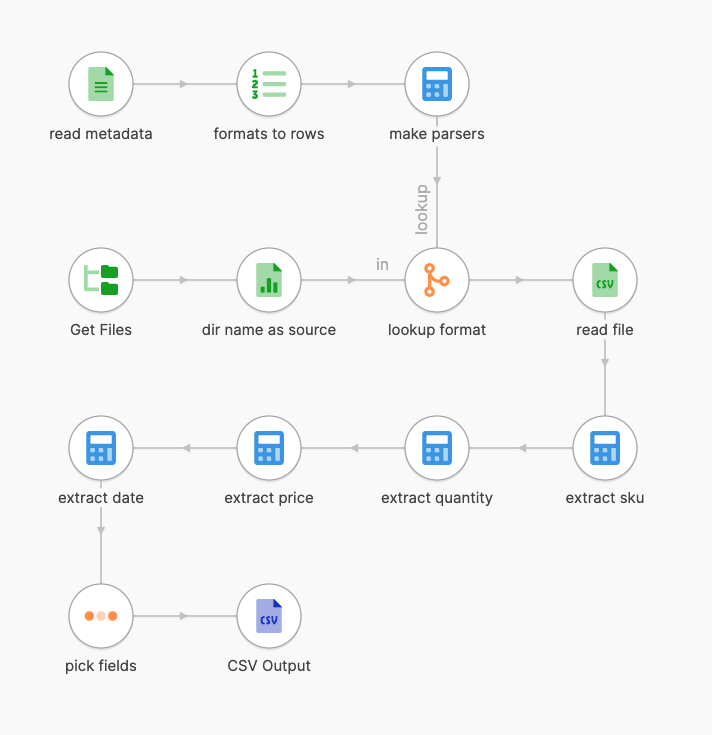
Part 1 - finding files to read
We first want to get a list of files to read. They all reside in our ./input directory.
The name of their subdirectory i.e. ./input/raymond_corp tells us which supplier we are looking at.
We can find all *.csv files, and extract the name of their parent directory.
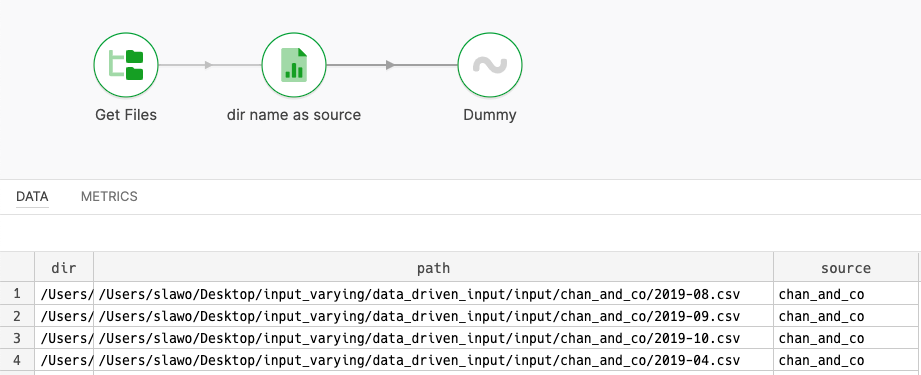
Part 2- reading metadata
We now need to pull in the metadata file. We can just read the JSON file into memory, and index them by source name for easy lookup.
We will eventually have to parse dates and prices using different formats. We create parsers for each format as well, and put them into rows.
We can then look up the correct format definition for each file.
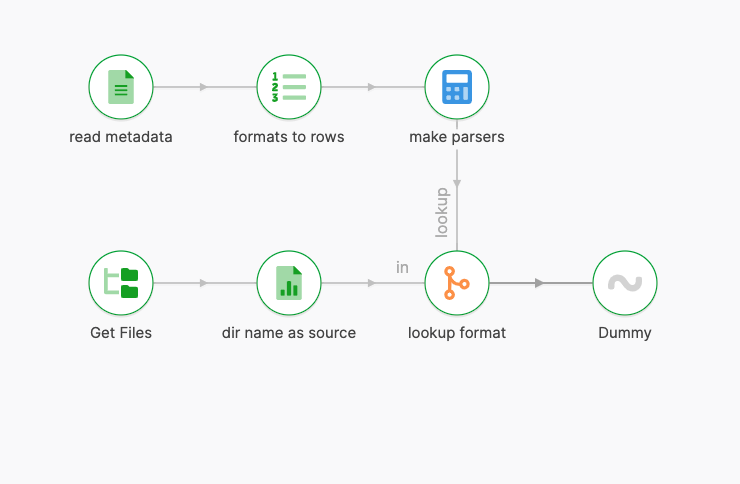
Part 3 - reading CSV lines
Reading CSV lines
We’d ready to read the CSV file now. We just have to put the information from our format definition into the corresponding settings of the CSV input step.
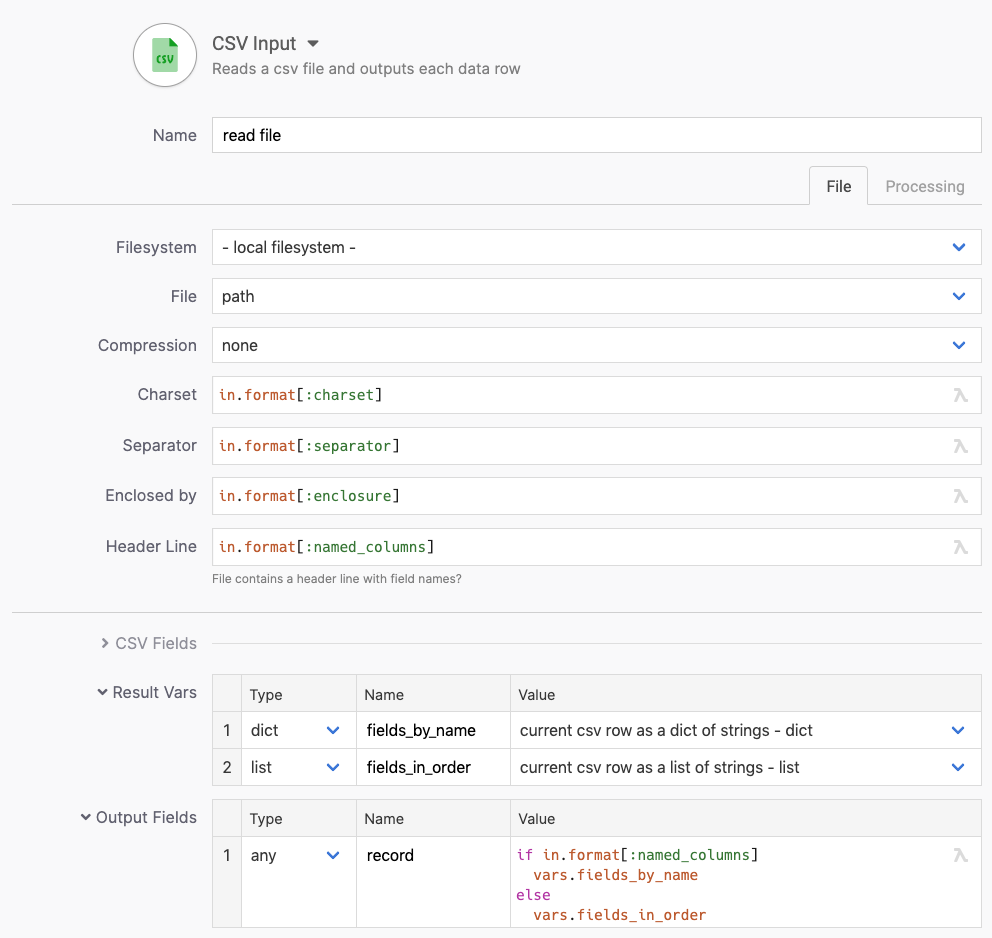
The CSV input step now reads the lines as configured by our format, and gives us a list of field values for each record.
If our format includes a header line, we can also access the field values by field names as included in the file.
We output a field called record which will be a dict in case we have field names, and a list if we do not.
Part 4 - extracting fields
We can now extract our fields of interest from CSV lines, based on our format information.
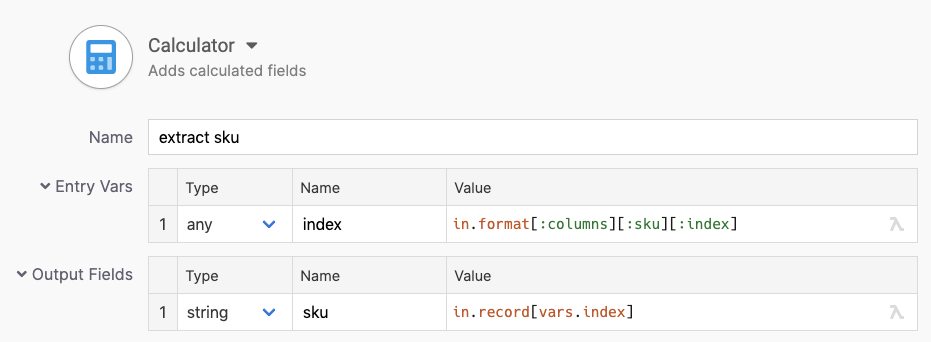
SKU
The sku field is easiest. It’s just a string that we need to grab from the right place.
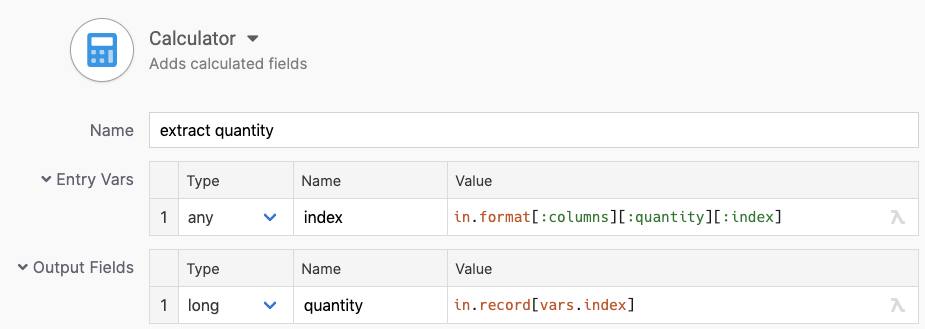
Quantity
The quantity field needs to converted to an integer number. We’re always getting a string made entirely of digits int this field, so we can just cast it to a long.
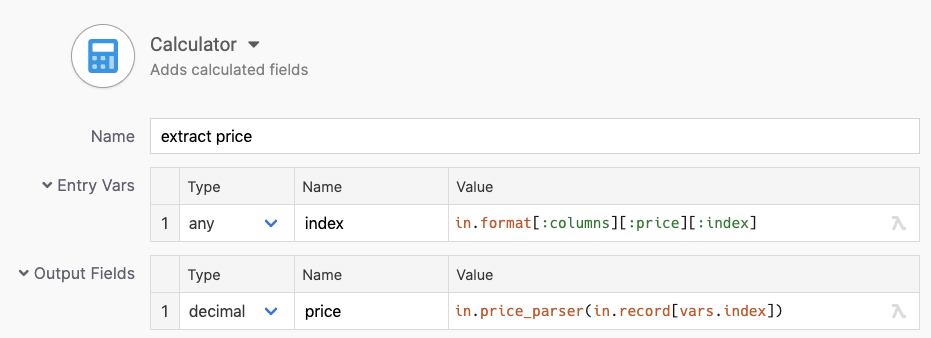
Price
The price field needs to be parsed into a decimal number. The location and parser are part of our metadata, so we get the value by invoking the parser on our input string.
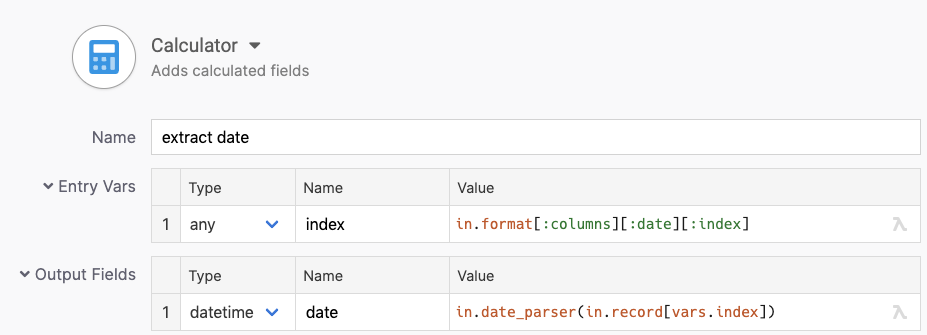
Date
The date field needs to be parsed into a datetime value. The location and parser are part of our metadata again.
Writing the output file
Once we’re done extracting fields, we can thin out the row structure and look at our data.
With all data rows present, we can output them to CSV using the CSV output step.
In Conclusion
We’ve created a consolidated version of all files. Our output.csv contains all data rows from various data inputs and looks as required:
source;date;sku;quantity;price
chan_and_co;2019-08-01;nil/s/gr;61;1036.39
chan_and_co;2019-08-01;rel/s/rd;58;667.00
chan_and_co;2019-08-01;nwa/m/rd;60;1343.40
...