Let’s do a basic data flow
We’ll create a data flow that:
- reads all records from a CSV file
- checks whether they look valid
- logs any invalid ones
Download and unpack your-first-data-flow.zip (4.2 KB) to follow along. It contains the data flow and CSV file. Open the validate.dfl data flow file.
The flow reads a CSV file that contains movies starring Robert DeNiro. Every movie has a release year and a score in range of 0-100.
| Year | Score | Title |
|---|---|---|
| 1968 | 86 | Greetings |
| 1970 | 17 | Bloody Mama |
| 1970 | 73 | Hi, Mom! |
| 1971 | 40 | Born to Win |
| 1973 | 98 | Mean Streets |
| 1973 | 88 | Bang the Drum Slowly |
| 1974 | 97 | The Godfather, Part II |
| 1976 | 41 | The Last Tycoon |
| 1976 | 99 | Taxi Driver |
| … | … | … |
The flow performs the following checks:
- verify the year is in range of 1960-2050
- verify the score is in range of 0-100
If any of the rows fail these tests, they are redirected to a branch that logs the row and the error.
Running the flow
Run the flow by right-clicking some empty space in the flow and selecting Run… from the context menu.
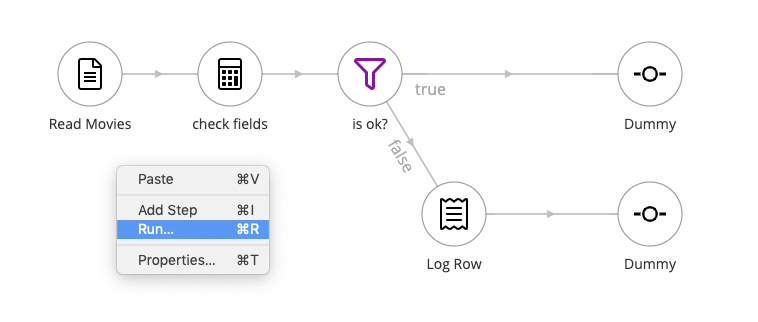
Confirm to run with default settings. We have no parameters to pass or settings to adjust.
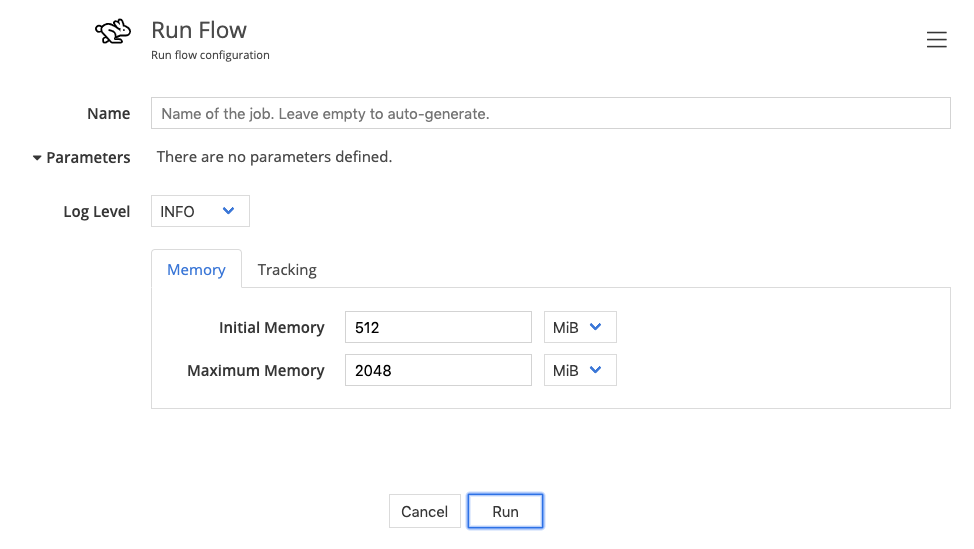
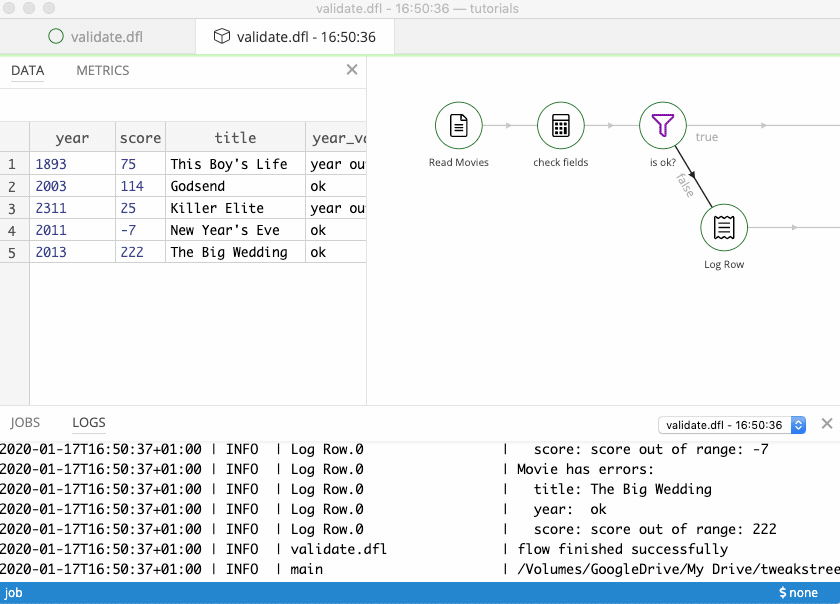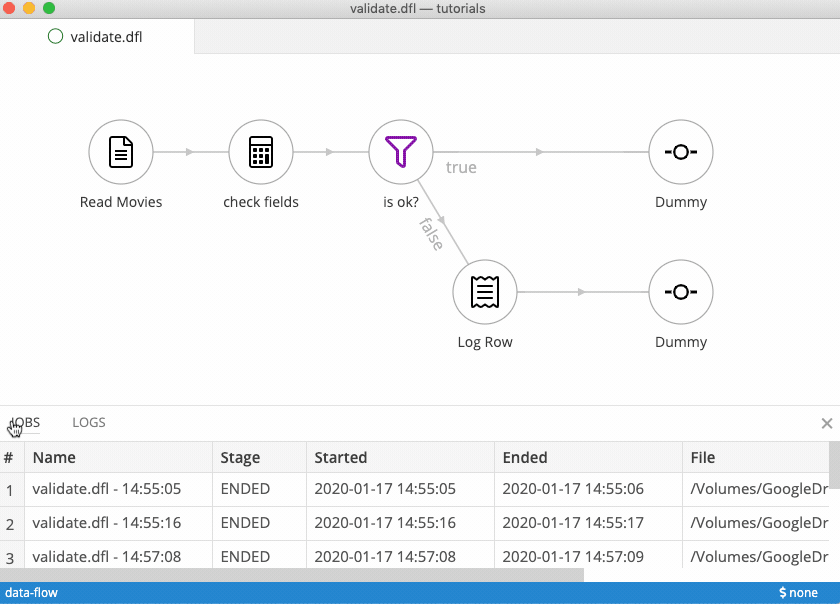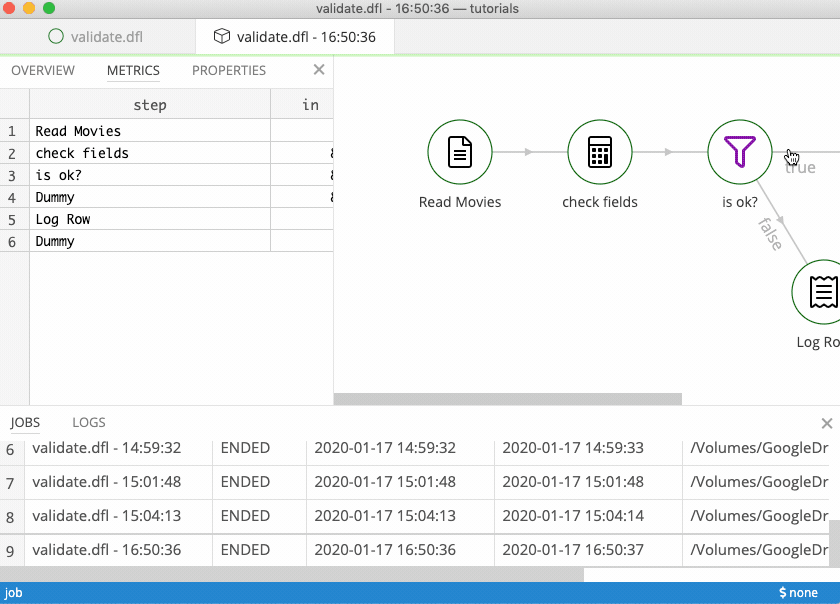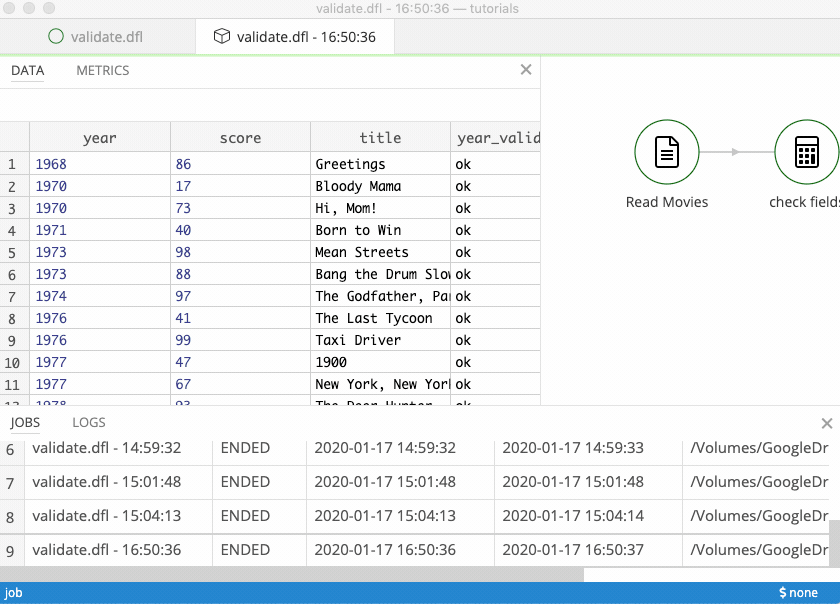
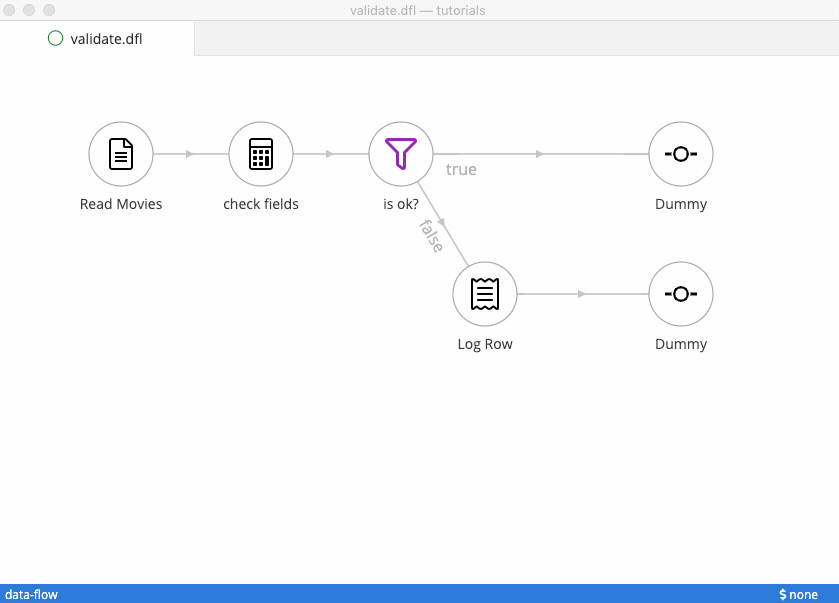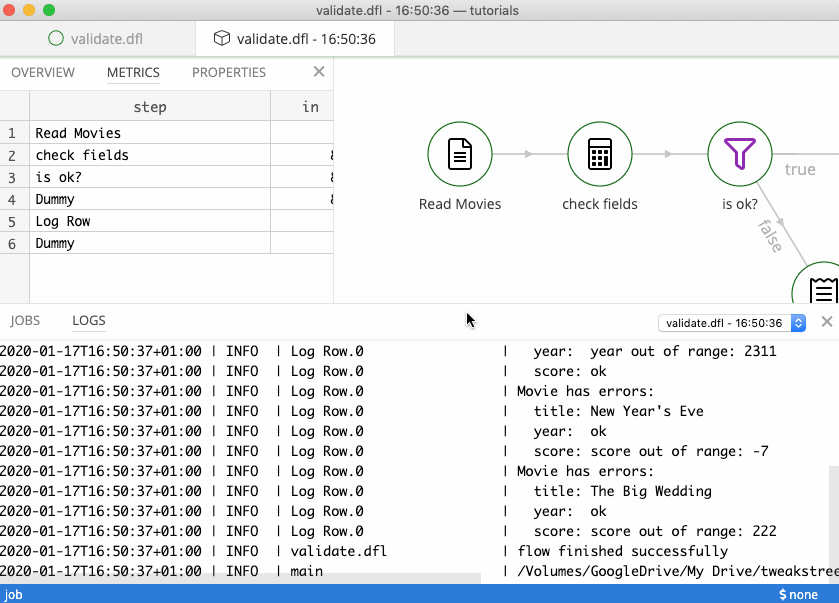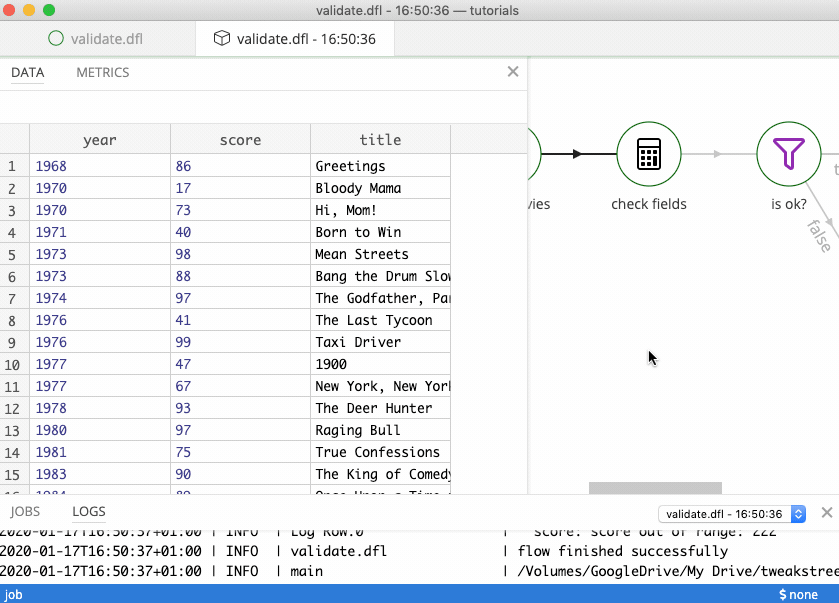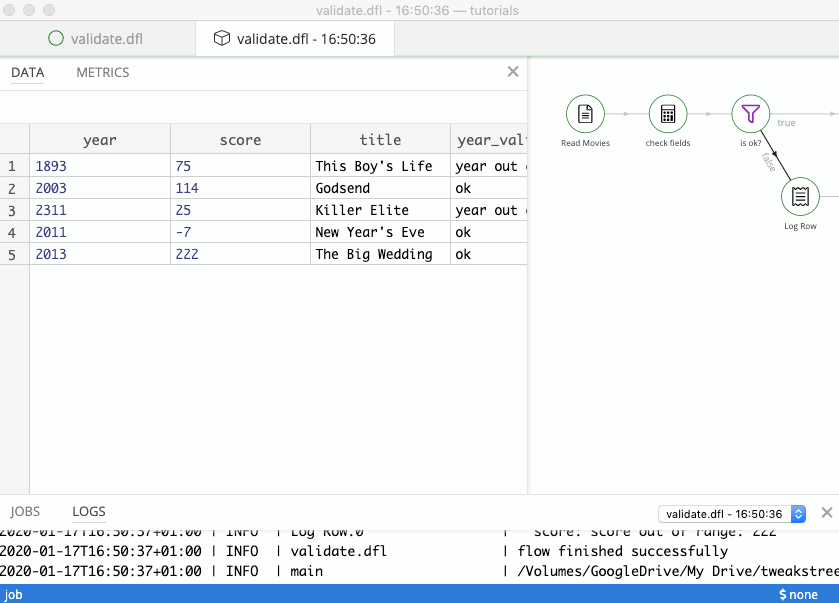
After running the flow we get the following result:
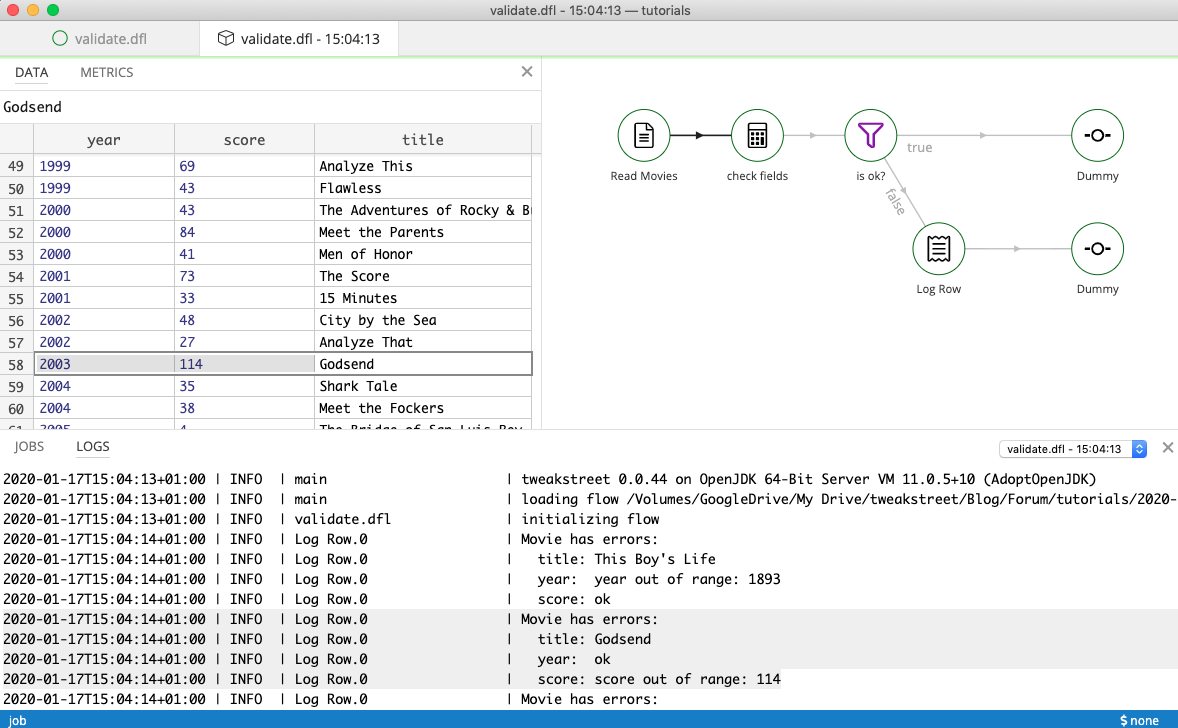
Looking at the run flow, you can click on hops to check which rows have passed through.
These records have made it through the filter:

And these were diverted as invalid:
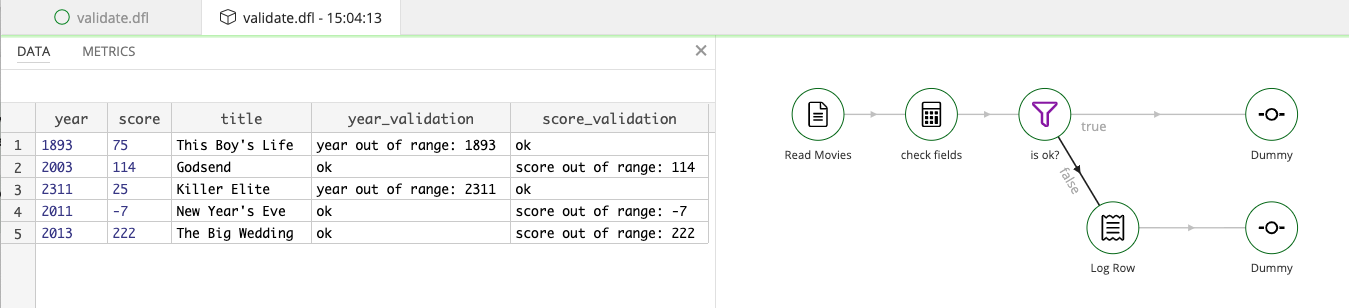
As you can see, dummy steps are useful as extra steps while building flows. If you connect them using an extra hop, you can inspect the output of the previous step.
Re-creating the demo flow from scratch
The following screencast video re-creates the demo file from start to finish:

If you’d rather follow written instructions: here we go!
First create a new data flow file and save it to disk.
To construct the flow elements you need to:
- add steps by right clicking empty space and choose “add step” from the menu
- configure steps by double-clicking on them
- connect steps by holding down shift, pressing the mouse button down on the source step, dragging to the target step, and letting go of the mouse button once the hop snaps into place
- configure source and destination gates of hops by right-clicking the gate’s name
Here’s a short demonstration of the basics:

Configuring the CSV input step

The CSV input step is instructed to read data from our movies.txt file. Note that paths beginning with ./ are interpreted as relative to the flow file.
The rest of the configuration is done according to the format of our CSV file. We have commas as separators, fields can be enclosed in quotes, and we have a header line.
After that is configured, a click on Auto-detect fields configures the fields automatically.
The Name column defines the names of the fields in our data flow, the Mapping column is the index into the CSV data. Since we have a header line, we can use column names as they appear in the header line. If there was no header line, we would use numeric column indexes.
Note that both year and score are detected as long integer fields and are parsed automatically for us.
Checking the year and score
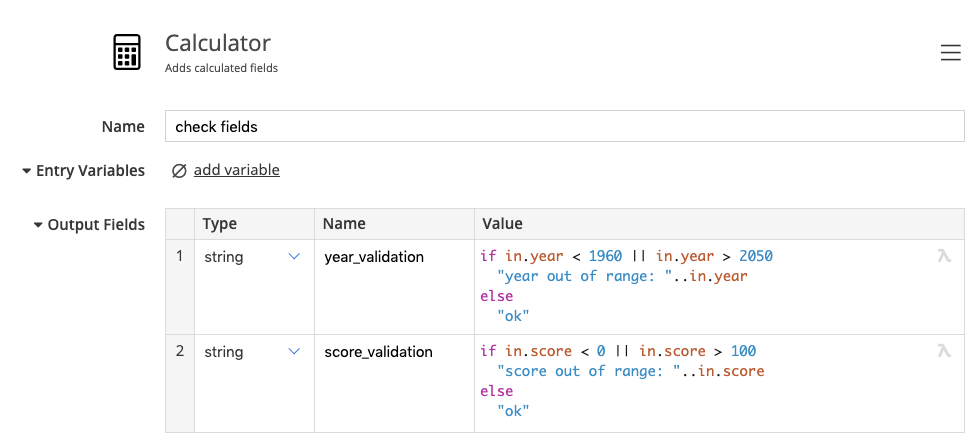
The calculator step calculates two validation fields for us using a conditional expression.
All formulas in tweakstreet are tweakflow expressions. We’re using the if conditional to produce either "ok" or an error message, based on the values of the input fields.
Note that in most steps - including the calculator step - you can reference field values as in.<field-name>
You can always press Ctrl+Space in a formula field to open an interactive box showing you the values you can use.
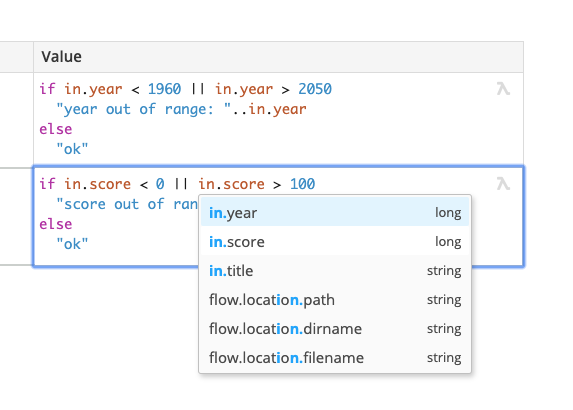
In our case we check whether the values are within acceptable bounds. The double pipe || is the logical or operator.
If a value is out of bounds, the error message includes the offending value. We use the string concatenation operator .. to append the offending value to the error message.
Note that if you want to re-create the calculator step validation from scratch, you might need to morph the field value widget to formula before you can enter your expression.

Redirecting invalid rows
The filter step forwards its input rows through one of two possible output gates.
For each input row a condition value is computed. If it evaluates to true, the row goes through the true output gate, otherwise it goes through the false output gate.
Our filter step checks to see if both of the validations we’ve done turned out as "ok"

We’re using the logical and operator to see if both validations the calculator step produces are equal to "ok".
Logging invalid rows
The Logger step outputs structured information to the log. We can specify a top level message and a list of values to log.
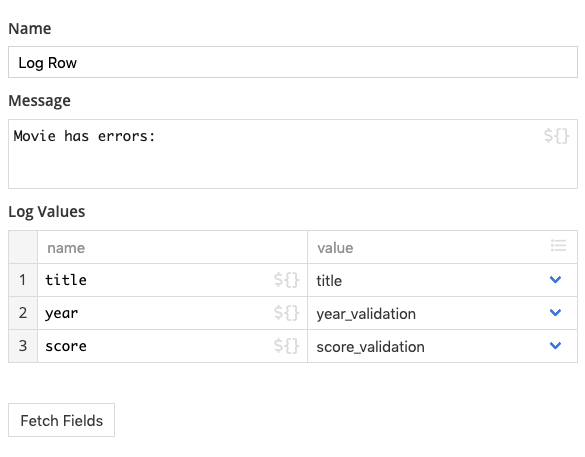
By default it logs the entire record. You can press the fetch fields button to automatically configure the step to log each field value individually. From there, you can adjust the configuration to log only fields of interest:
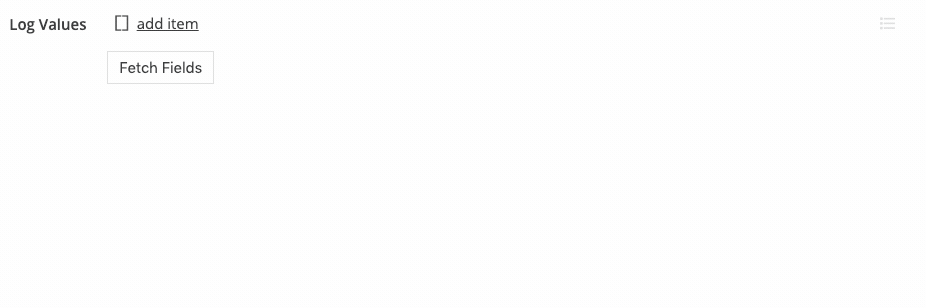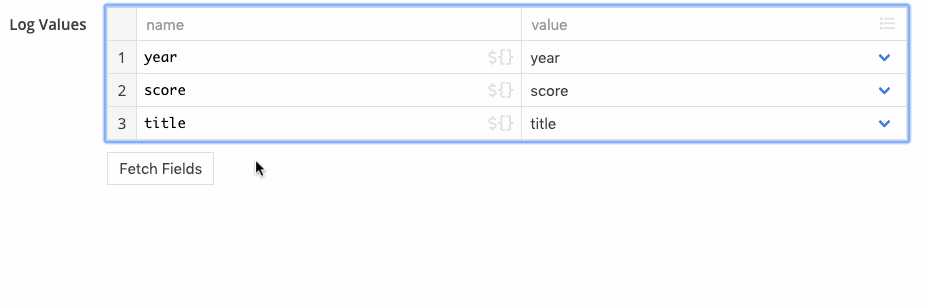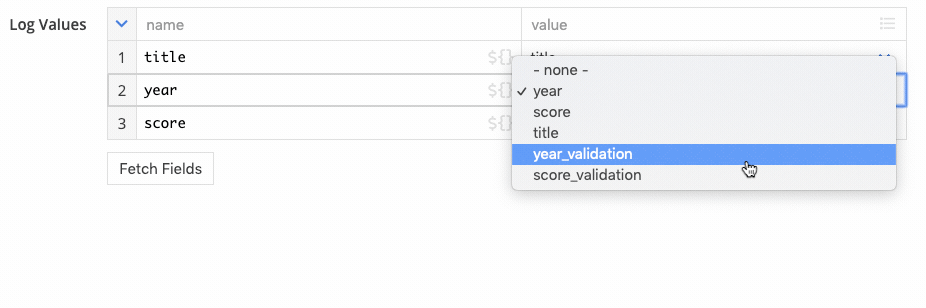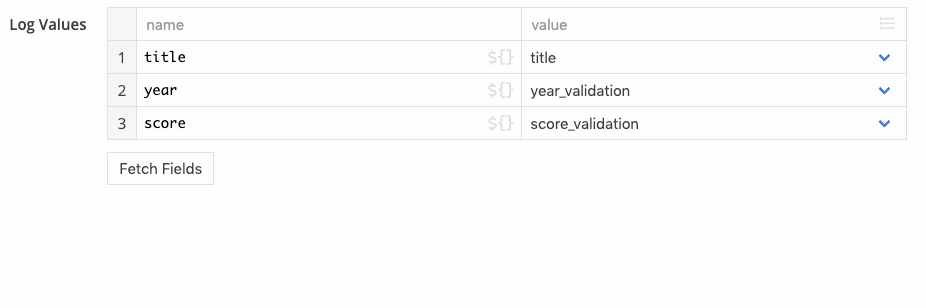
Running your flow
You can run your flow by right clicking empty space on the canvas and selecting “Run…”. A new tab will open that holds the results of the job you run. You can inspect the data flowing through your solution by clicking on the hops.
If you want to go back to your working on your flow, switch back to your flow tab.
You can safely close the job tab. You can reopen it from the jobs section at any time. Tweakstreet remembers the most recent job executions for you, and you can re-open them for inspection at any time.